Trong số tất cả các nghiên cứu thực tế về mạng thần kinh, machine learning, và trí tuệ nhân tạo đang được tiến hành, có rất nhiều thử nghiệm…xàm xí mà kết quả nằm ở lằn ranh mong manh giữa thú vị và đáng sợ.
Xử lý hình ảnh tự động thời gian qua đã nổi lên như một công cụ tuyệt vời của các mạng thần kinh nhân tạo, một phần nhờ hàng thập kỷ chia sẻ ảnh chụp và ảnh selfie của mọi người lên internet. Kết quả là chúng ta có một kho ảnh chụp khuôn mặt khổng lồ để "thu hoạch" và sử dụng và việc huấn luyện AI làm mọi thứ, từ việc giả lập quá trình lão hóa người dùng trên các ứng dụng di động, đến tạo ra những bộ sưu tập ảnh khuôn mặt siêu thực của những người thậm chí còn chẳng hề tồn tại.
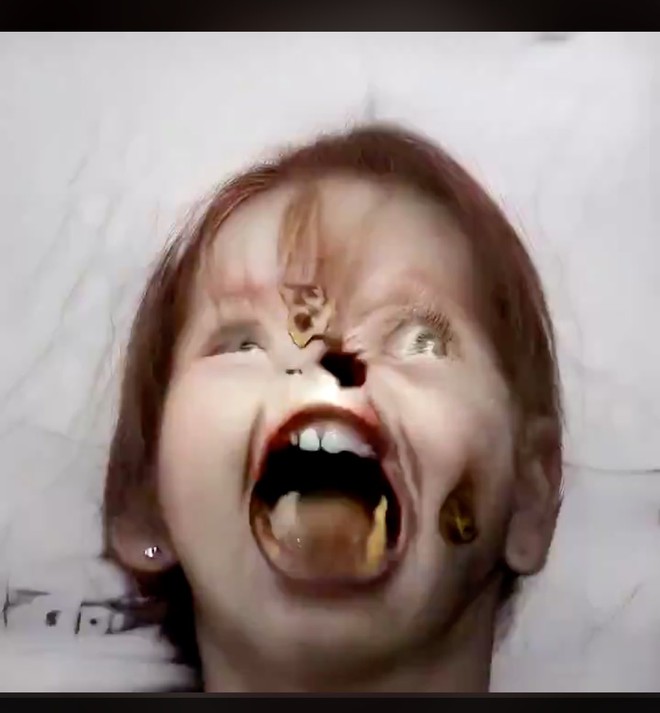
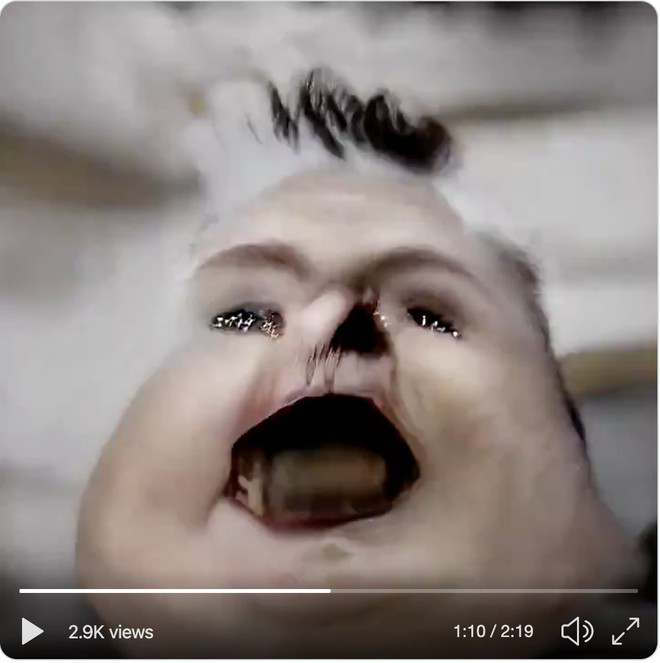
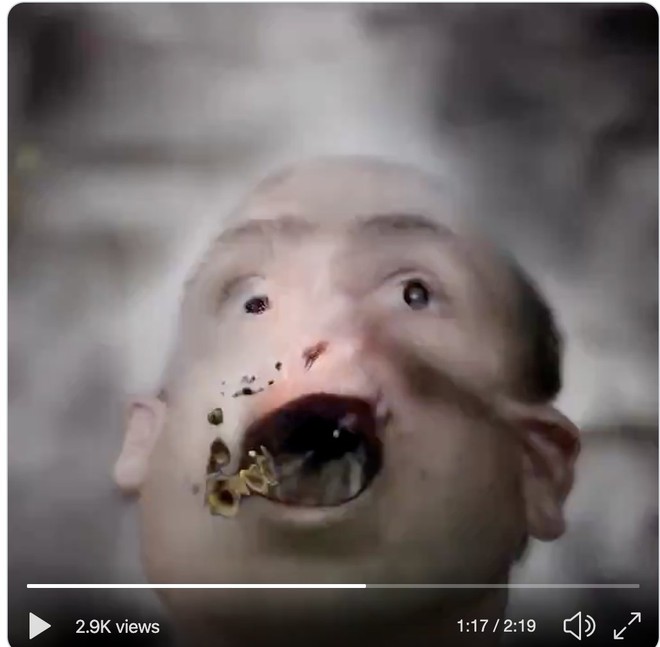
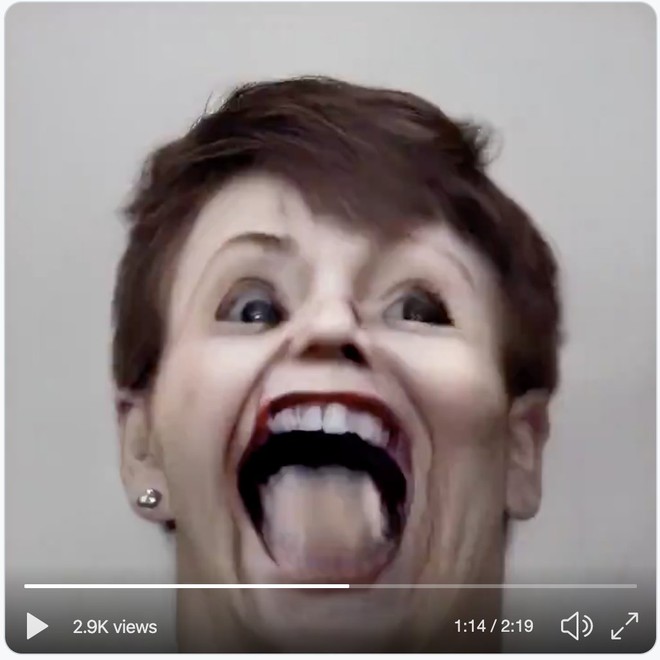
Ngành công nghiệp ảnh stock sẽ không bao giờ như trước nữa, nhưng anh chàng Mario Klingermann tự hỏi điều gì sẽ xảy ra nếu yêu cầu những mạng thần kinh nhân tạo kia tạo ra những ảnh chụp khuôn mặt ảo đồng bộ với điệu nhạc – và như bạn thấy trong video dưới đây, chúng ta có một vài khuôn mặt thực sự ấn tượng khi tiếng nhạc đập bùm bùm!
Klingermann đã sử dụng mạng nghịch đảo phát sinh StyleGAN2, vốn được tạo ra bởi Nvidia và sau đó tung ra dưới hình thức mã nguồn mở hơn 1 năm trước. Anh này không hề tự mình thực hiện quá trình huấn luyện hình ảnh tùy biến, mà thay vào đó là tinh chỉnh GAN để nó biến chuyển các kết quả tạo ra dựa trên phổ âm thanh của một tập tin âm thanh đưa vào – trong trường hợp này là bài hát Triggernometry của Kraftamt.
Một vài người theo dõi Twitter của Klingermann đã nói rằng anh nên cho đoạn video do GAN tạo ra chạy chậm lại một chút để thấy được những thứ kinh dị ẩn trong đó. Các bạn có thể xem các hình ảnh bên dưới sẽ thấy sự kinh dị của nó ngay. Chú ý là bạn không nên kéo xuống xem tiếp nếu có tiền sử tim mạch hoặc đang xem bài viết này vào lúc nửa đêm nhé!
* Cảnh báo lần cuối đấy nhé!


Theo GenK